First UDF & basics
Fused
Fused makes it easy to run Python at scale. You write Python code, and Fused handles execution, scaling, and API generation automatically.
If it runs locally, it runs on Fused — at scale.
It decouples what you write from how it runs and where it goes.
UDFs
UDFs (User Defined Functions) are Python functions with a @fused.udf decorator that return data. Each UDF becomes its own API endpoint with a unique URL.
Try it in Workbench:
@fused.udf
def udf(name: str = "Fused"):
import pandas as pd
return pd.DataFrame({'message': [f'Hello {name}!']})
A UDF needs:
- The
@fused.udfdecorator - A function (called
udf) - Parameters with type hints and default values
UDFs can return tables (DataFrame, GeoDataFrame), arrays (numpy, xarray), or simple Python objects. Learn more about writing UDFs.
Data
Bring your own data into Fused:
- Drag & drop — Drop local files directly into Workbench
- Cloud storage — Read from S3, GCS, or Azure (public or connect your own bucket)
- Databases — Read from Snowflake, BigQuery, or other databases
- APIs — Fetch from any HTTP endpoint
@fused.udf
def udf():
import pandas as pd
return pd.read_csv("s3://your-bucket/your-data.csv")
Need credentials for private data? See secrets management.
Formats
Share your canvas to get a canvas token; then each UDF is available by name.
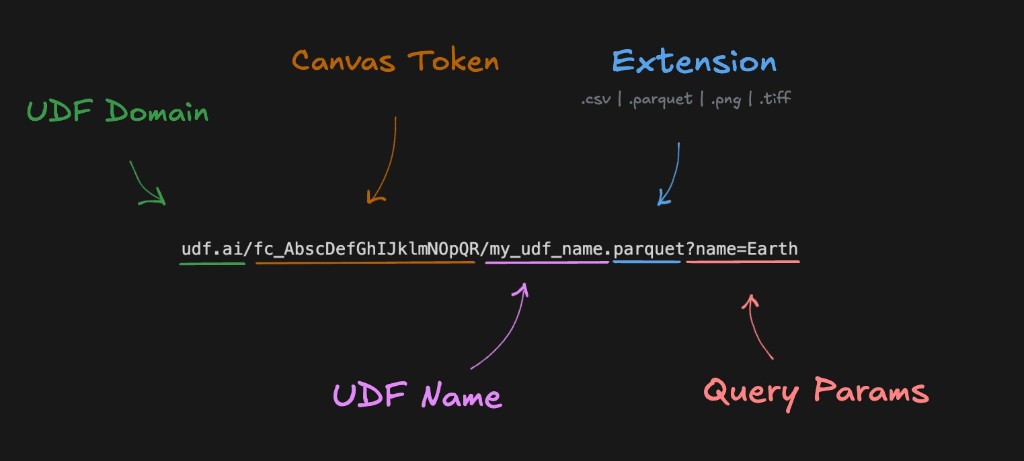
Every UDF is a dynamic file system. Same UDF, multiple output formats. Change the URL extension to get JSON, CSV, Parquet, PNG, TIFF, or MVT; no code changes needed!
https://udf.ai/fc_<CANVAS_TOKEN>/my_udf.json
https://udf.ai/fc_<CANVAS_TOKEN>/my_udf.csv
https://udf.ai/fc_<CANVAS_TOKEN>/my_udf.parquet
Pass parameters via URL to change outputs dynamically:
https://udf.ai/fc_<CANVAS_TOKEN>/my_udf.json?name=World
Learn more about Calling UDFs as API.
Caching
First request runs your code. Subsequent requests (same code, same parameters) return cached results in under a second. UDFs are cached for 14 days by default.
Try it yourself:
@fused.udf
def udf():
import time
time.sleep(5)
return {"status": "done"}
Run once → 5 seconds. Run again → ~1 second (cached).
Set any cache duration you need, including 0 to force a fresh run every time:
@fused.udf(cache_max_age="0s")
def udf():
import time
time.sleep(5)
return {"status": "done"}
Learn more about caching.
Pipelines
UDFs can call other UDFs to build data pipelines. Each stays standalone with its own endpoint.
# UDF 1: load_cities
@fused.udf
def udf(continent: str = "Europe"):
import pandas as pd
cities = pd.DataFrame({
"city": ["London", "Paris", "Berlin", "Tokyo", "Sydney"],
"population": [9, 2, 4, 14, 5],
"continent": ["Europe", "Europe", "Europe", "Asia", "Oceania"]
})
return cities[cities.continent == continent]
# UDF 2: big_cities
@fused.udf
def udf(continent: str = "Europe", min_pop: int = 3):
load_cities = fused.load('load_cities')
cities = load_cities(continent=continent)
return cities[cities.population >= min_pop]
Here, fused.load("load_cities") loads the saved UDF named load_cities. It returns a callable UDF object, so load_cities(continent=continent) calls the load_citites UDF and runs it.
You could also run load_cities(continent=continent, engine='local') locally inside the current UDF. This can help limit the number of UDF instances you run at the same time, especially for small functions.
big_cities calls load_cities and passes through the continent param. Both UDFs have their own API endpoint — call either one directly:
https://udf.ai/fc_<CANVAS_TOKEN>/my_udf.json?continent=Asia&min_pop=5
Organise UDFs visually in Canvas — connect them, build workflows, create dashboards.