FAQ
General questions
Whom is Fused for?
Fused is built for individuals & teams wanting to get things done quickly with data.
From building quick prototypes with AI by dragging & dropping a dataset to start working with, to making professional dashboards with large dashboards.
Which authentication methods do you support?
Fused currently uses Auth0 to support authentication via Google and GitHub.
Troubleshooting
Status page
Access our status page at any time to check on Workbench & API status
Common Errors
Error: Access is not configured for you in the Fused Workbench. Please refresh the page if you think this is an error, or get in touch if you require further help. Cause: Realtime instance not configured.
This error occurs when you try to run a UDF with an account associated with a workspace environment that does not have a realtime instance configured. This means that there are no worker nodes available to run the UDF. To resolve this issue, please get in touch with the Fused team team to ensure your account is associated with an environment with a realtime instance.
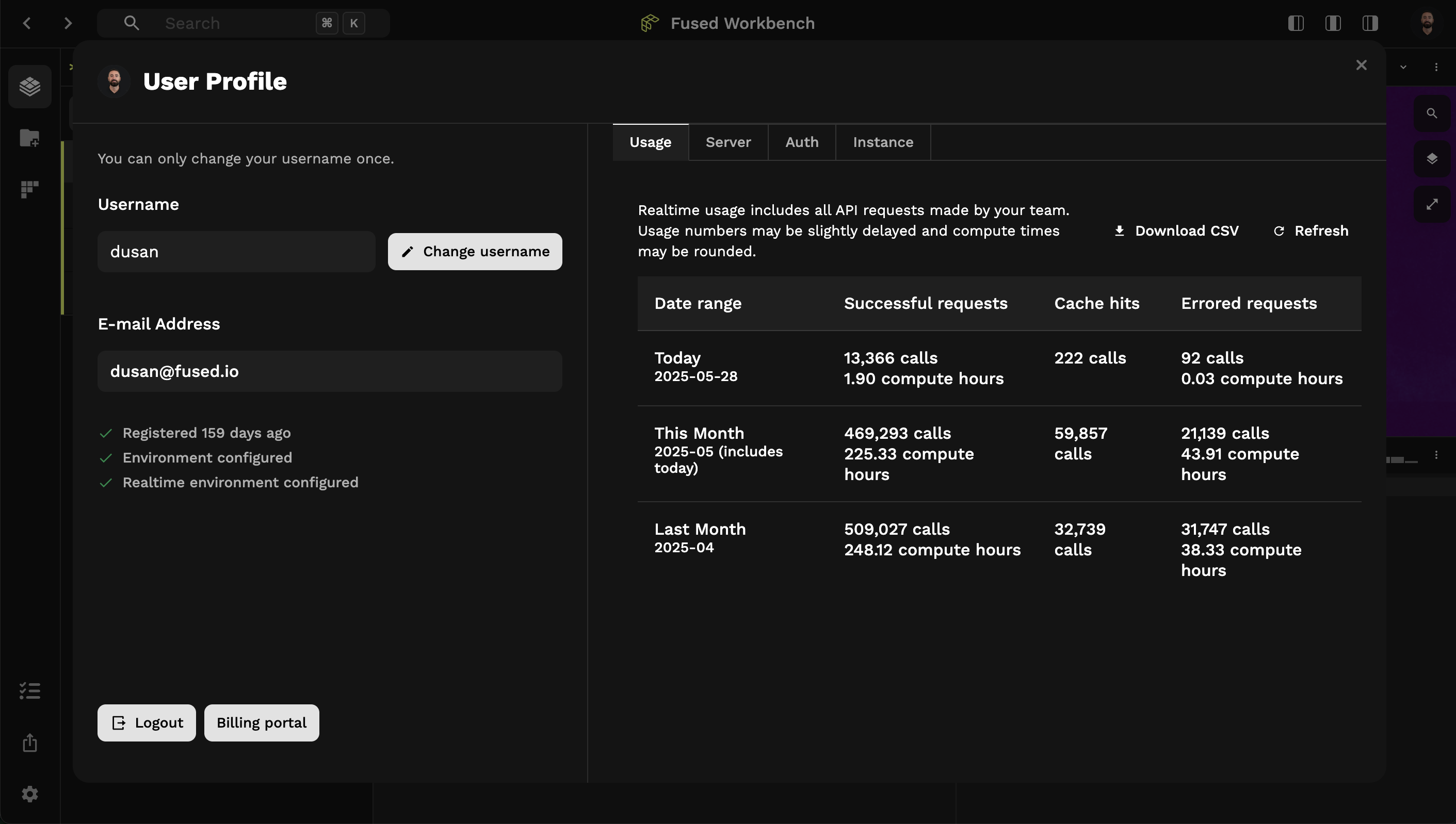
When Troubleshooting this error, it may help to navigate to your account's User Profile page to determine if the account is associated with an environment and realtime instance, as shown here.
Error: No such file or directory: '/mnt/cache/'
This error occurs when a UDF attempts to access the /mnt/cache disk when it is not available for the environment. To resolve this issue, please contact the Fused team to ensure that the cache directory is available for your account.
Error: No space left on the device: '/tmp/'
This error occurs when a UDF attempts to write more data than the /tmp directory of the real-time instance can handle. Realtime instances have a limited amount of space available and are ephemeral between runs. You might want to consider writing to /mnt/cache disk instead.
Error: Quota limit: Number of running instances
Error: Application error: a client-side exception has occurred (see browser console for more information).
In the case that you encounter this error, please reset your browser cache and cookies. If the error persists, please contact the Fused team for further assistance.
Error: MY_UDF... not saved because a UDF or app wit that name already exists.
It's possible you might be editing a "local" UDF that has the same name as a Team UDF. To resolve this issue, you can either rename the UDF or, if your intention is to update the Team UDF, Push it to GitHub.
Error: Failed to create share token: {"detail":"UDF not found"}
To resolve this error, save the UDF again and refresh your browser. If you use canvas sharing, make sure you’ve shared the canvas first. If the problem persists, rename the UDF and try again.
Error: ModuleNotFoundError: No module named 'geopandas' / 'xarray'
This error happens when your UDF returns a GeoDataFrame or an xarray Dataset but your local env doesn't have the geopandas or xarray package installed to manipulate it.
The standalone fused package doesn't have geopandas or xarray or other optional dependencies installed to keep it light weight.
This can be fixed in 2 ways:
- When running fused locally
You can install fused with all the optional dependencies:
pip install "fused[all]"
- When running a UDF in a Fused App
Install the package using micropip at the top of your app:
import micropip
await micropip.install(['geopandas'])
# await micropip.install(['xarray']) # if you were missing xarray
import geopandas as gpd
You can install multiple packages the same way:
await micropip.install(['geopandas', 'xarray'])
Workbench Memory Usage tells me "Unknown"
We try our best to retrieve memory usage for UDFs you run in Workbench to help you monitor & optimize your UDFs.
There are a few reasons why we might not be able to retrieve memory usage:
- Running a shared token, for example a public UDF: In this case we don't share memory usage as the original builder of the UDF might not want to reveal the inner workings of their UDF.
- Running a cached UDF: If you're running a UDF that was cached (rerunning the same UDF with the same parameters), no memory was used.