DuckDB
Fused runs User Defined Functions (UDFs) behind HTTP endpoints. DuckDB can call those endpoints and run SQL on their output.
This guide provides support material for the blog post DuckDB + Fused: Fly beyond the serverless horizon. It can be followed in this Jupyter Notebook.
1. Run DuckDB in a Fused UDF
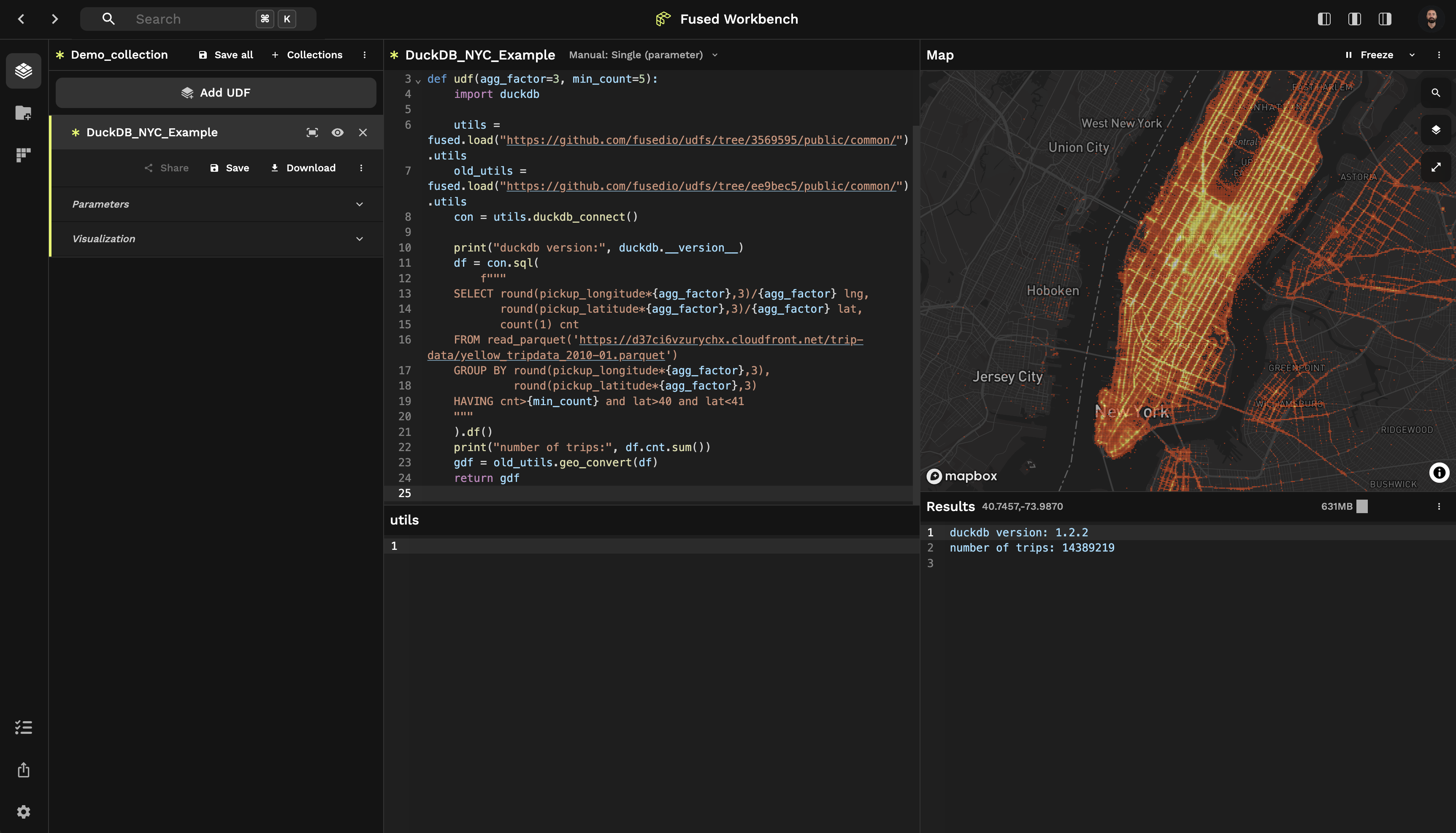
As an example of running DuckDB within a Fused UDF, take the case of loading a geospatial Parquet dataset. The "DuckDB H3" sample UDF runs an SQL query with DuckDB on the NYC Taxi Trip Record Dataset. It uses the bounds argument to spatially filter the dataset and automatically parallelize the operation.
To try this example, you can run the cell below. You can find the code of the UDF in the Fused public UDF repo. Alternatively, you can import the "DuckDB H3 Example Tile" UDF into your Fused Workbench environment.
This pattern gives DuckDB easy parallel operations. Fused spatially filters the dataset via the `bounds parameter, runs the operation for each encompassing tile, and stitches the results together. Because Fused breaks down operations to only a fraction of the dataset, it's easy to transition between SQL and Python.
import fused
udf = fused.load("https://github.com/fusedio/udfs/tree/ea99f07/public/DuckDB_H3_Example_Tile")
gdf = fused.run(udf=udf, x=2412, y=3078, z=13, engine='local')
gdf.head()
2. Call Fused UDFs from DuckDB
Any database that supports querying data via HTTP can call and load data from Fused UDF endpoints using common formats like Parquet or CSV. This means that DuckDB can dispatch operations to Fused that otherwise would be too complex or impossible to express with SQL, or would be unsupported in the local runtime.
As an example of calling a Fused endpoint from within DuckDB, take an operation to vectorize a raster dataset. This might be necessary to determine the bounds of areas with pixel value within a certain threshold range in an Earth observation image - such as a Digital Elevation Model. SQL is not geared to support raster operations, but these are easy to do in Python.

In this example, a Fused UDF returns a table where each record is a polygon generated from the contour of a raster provided by the Copernicus Digital Elevation Model as a Cloud Optimized GeoTIFF. DuckDB can easily trigger a UDF and load its output with this simple query, which specifies that the UDF endpoint returns a Parquet file.
This SQL query uses DuckDB's read_parquet function to call an endpoint of a UDF instance of the "DEM Raster to Vector" UDF.
You can find the code of the UDF in the Fused Public UDF repo.
To try this example, simply run the following SQL query on the cell below or in a
DuckDB shell.
Change the min_elevation parameter to run the UDF for parts of California at different
elevations. (Note: for DuckDB WASM, the file will be requested as CSV.)
import duckdb
con = duckdb.connect()
con.sql("""
SELECT
wkt,
ROUND(area,1) AS area
FROM read_parquet('https://www.fused.io/server/v1/realtime-shared/1e35c9b9cadf900265443073b0bd99072f859b8beddb72a45e701fb5bcde807d/run/file?min_elevation=500&dtype_out_vector=parquet')
LIMIT 5
""")
This pattern enables DuckDB to perform operations and handle data formats that would otherwise be challenging or impossible, such as raster operations, API calls, and control flow logic.
3. Integrate DuckDB in applications using Fused
Fused can act like the glue layer between DuckDB and other 3rd party apps. It enables seamless integrations that trigger Fused UDFs and load their results with simple parameterized HTTP calls.
DuckDB is an embedded database engine and doesn't have built-in capability to share results other than writing out files. With Fused, DuckDB can query and transform data and seamlessly integrate the results into any workflow or app.
As an example, take the case of loading the output of a DuckDB query into Google Sheets.
Sheets can easily structure the Fused UDF endpoint to pass parameters defined in
specific cells as URL query parameters. In this example, the
importData command calls the
endpoint for the UDF above and loads its output data in CSV format. It constructs the
endpoint string by concatenating a base URL with the B2, B3, and B4 cell values as
query parameters.
=importData(CONCATENATE("https://www.fused.io/server/v1/realtime-shared/aba7b238d9445d576e15b2d6b780dc353bfdee55f02a285a85a3917b72835600/run/file?dtype_out_vector=csv&resolution=", B2, "&min_count=", B3, "&head=", B4))

To try this example simply make a copy of
this
Google Sheets spreadsheet (File > Make a copy) and click, and modify the parameters in
B2:4 to trigger the Fused UDF endpoint and load data.
This pattern brings the power of DuckDB no-code tools like Google Sheets, Retool, and beyond - without the need to build bespoke integrations with closed-source systems. With this, a Python developer can abstract away the UDF and deliver data to end users.