
News
The Modern Data Stack Is Dead. Who Killed It?
April 30, 2026Max Lenormand, Isaac Brodsky, Sina Kashuk

News
Introducing Fused AI Canvas
October 30, 2025Sina Kashuk, Isaac Brodsky

Use cases
Building Geospatial Real-Time Analysis in Fused
October 24, 2025Christopher Kyed
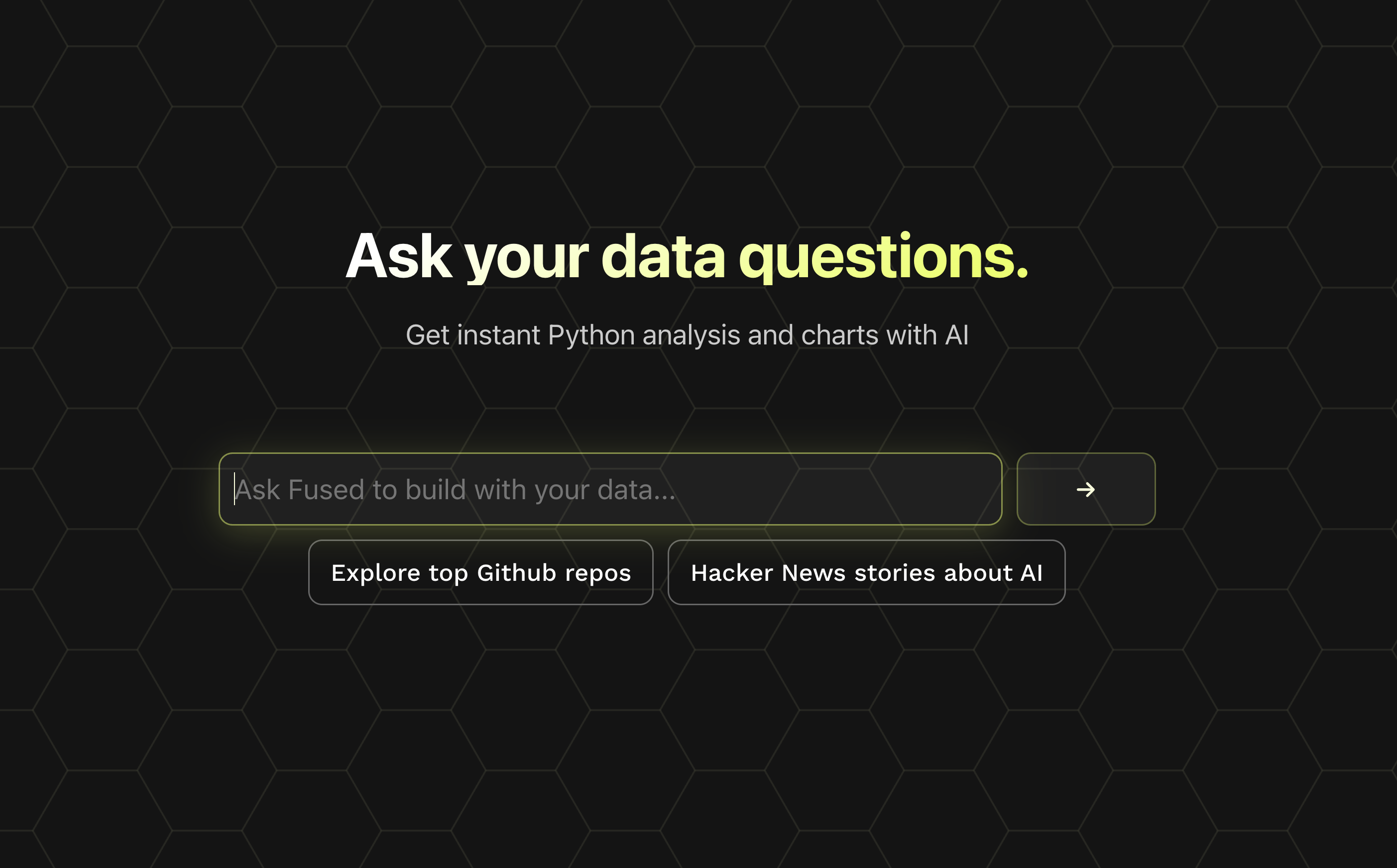
News
Analytics is Changing (Again)
August 1, 2025Sina Kashuk, Isaac Brodsky, Max Lenormand

News
Fused is SOC2 Type 1 Compliant!
July 8, 2025Isaac Brodsky, Max Lenormand

News
Notes from EO Summit 2025
June 19, 2025Max Lenormand

Use cases
Scaling Environmental Insights with Fused and H3
May 27, 2025Emma Quirk, Majid Alivand

Technical blogs
Inside Fused Apps: Python in The Browser
May 20, 2025Isaac Brodsky, Max Lenormand

News
Launching Fused Apps
May 20, 2025Sina Kashuk, Max Lenormand

Use cases
How Sylvera uses Fused to prototype and power DeckGL applications
May 16, 2025Daniel Jahn
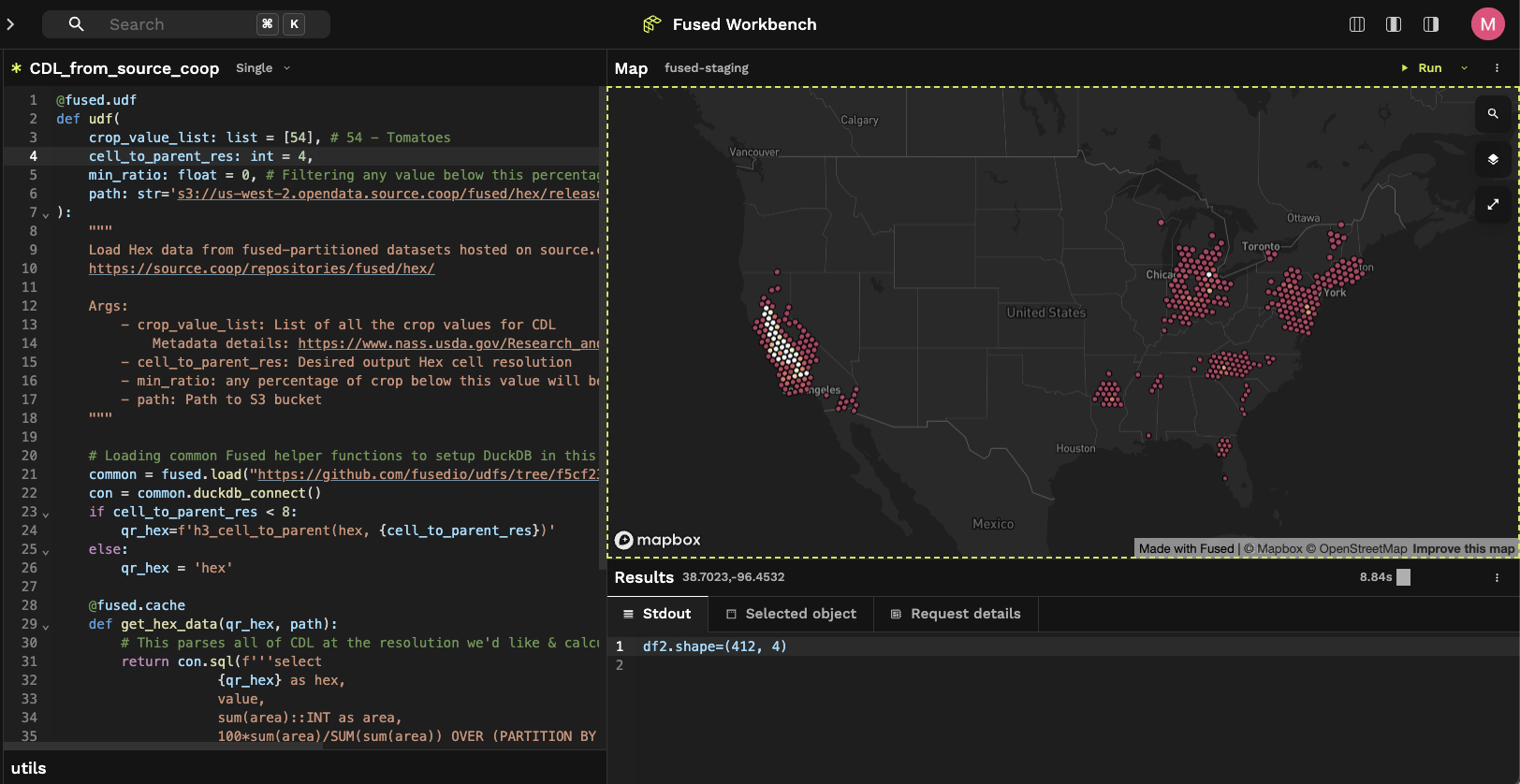
News
Repartitioning Crop Data Layer & US Census into H3 hexagons
May 6, 2025Max Lenormand, Sina Kashuk

News
Fused featured in Maxar TED Talk
April 8, 2025Isaac Brodsky, Sina Kashuk
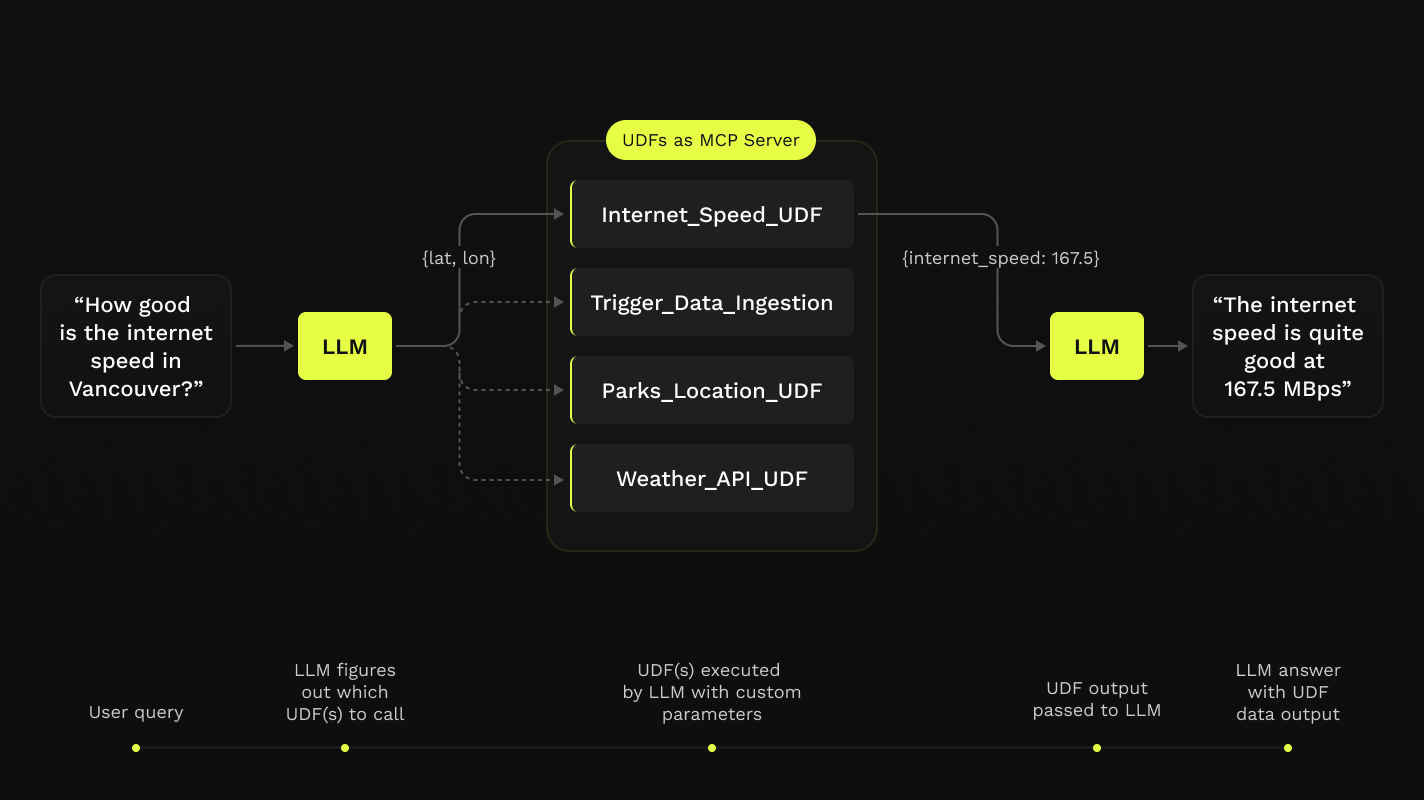
News
Announcing Fused AI Builder
April 1, 2025Max Lenormand
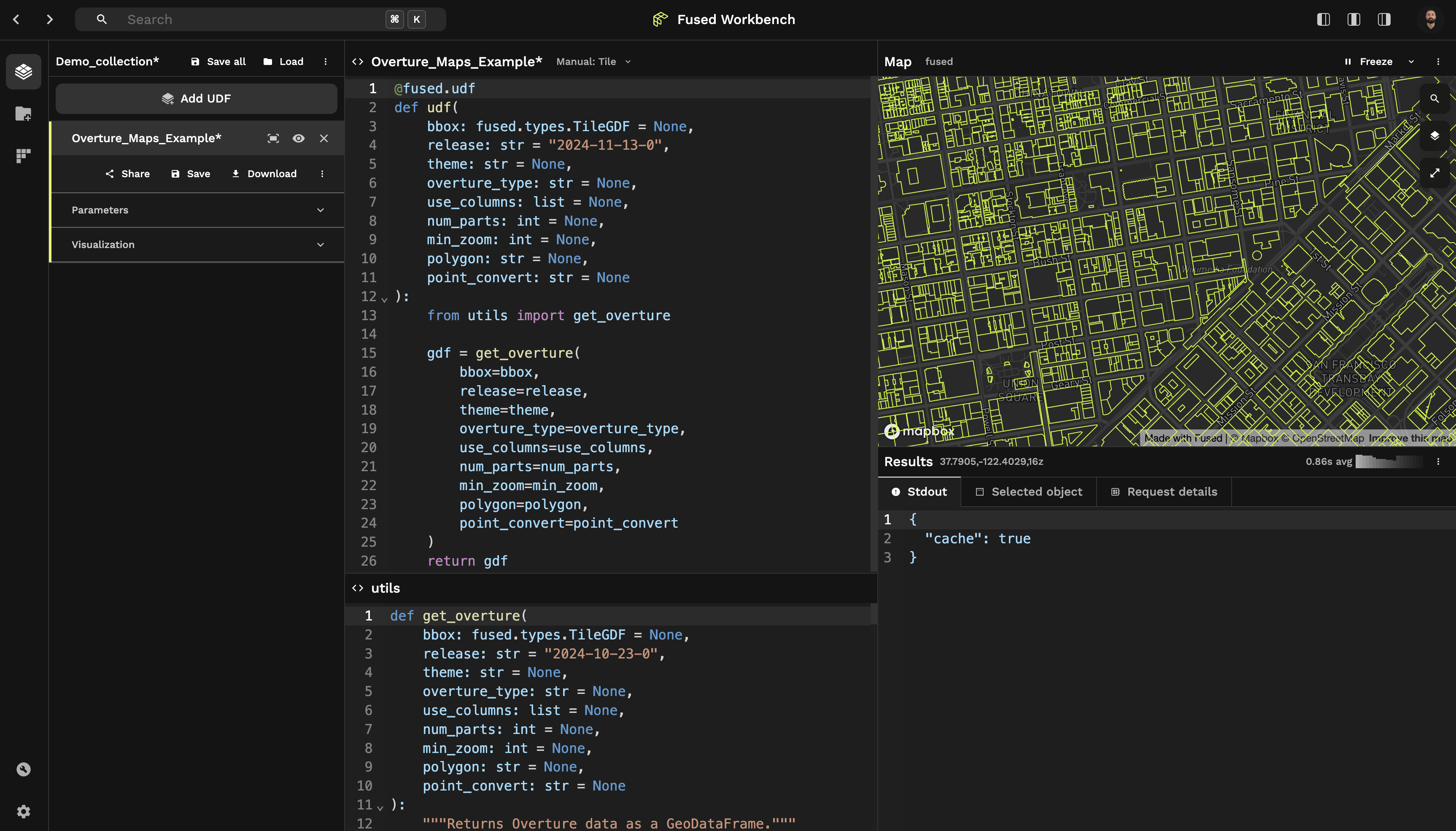
News
Announcing Fused 2.0
February 25, 2025Max Lenormand

Use cases
Enhance your data with GERS IDs
February 18, 2025Jennings Anderson, Plinio Guzman
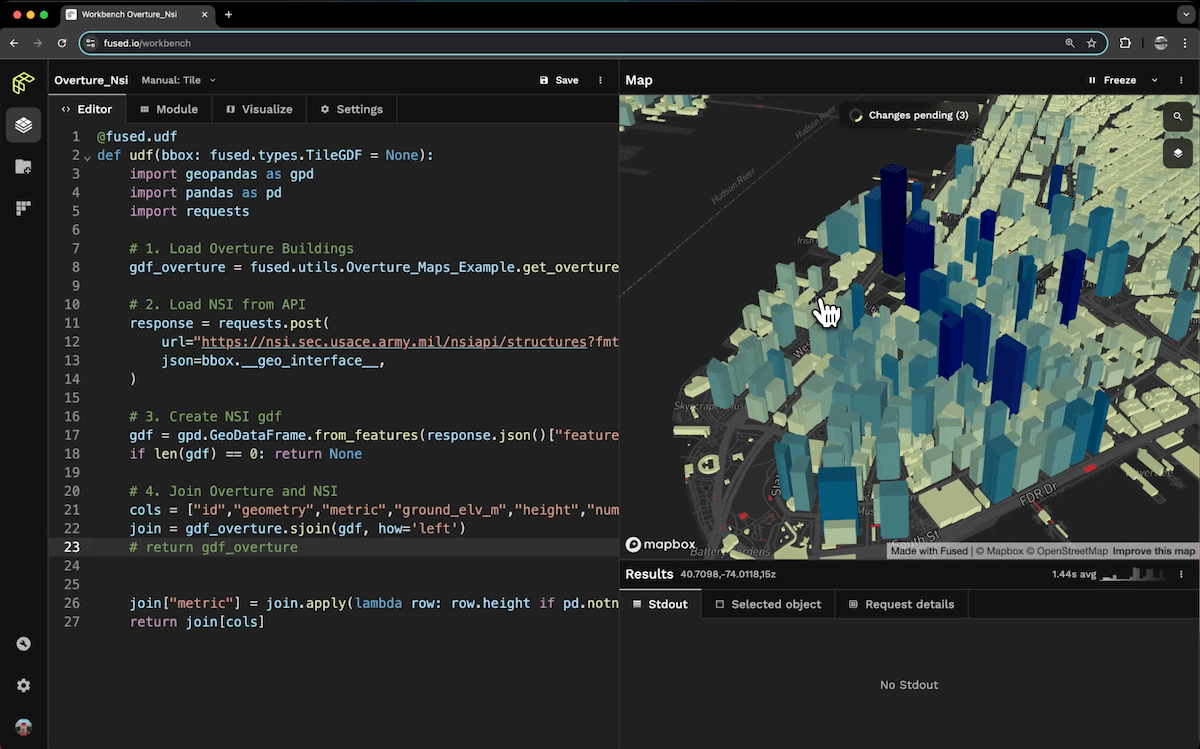
News
We're partnering with Overture to make their Data easily accessible with Fused
February 11, 2025Jennings Anderson, Plinio Guzman

Use cases
How Pilot Fiber creates internal tools to support telecom operations
January 23, 2025Kyle Pittman, Nelina Huang

Use cases
How Fused Powers BlackPrint's Acquisition Intelligence Platform
January 22, 2025Gilberto S. Perezalonso

Use cases
Hot-spot analysis for invasive species using Overture Maps
January 21, 2025Elizabeth Rosenbloom

Use cases
Calculating Fire Ratings with Overture Buildings and Places
January 20, 2025Chris Amico, Plinio Guzman

Use cases
Characterize cities with embeddings of Overture Place categories
January 16, 2025Maribel Hernandez

Use cases
Streamlining the design of parcel delivery routes with H3
January 9, 2025Antonius Moosdorf

Use cases
The Strength in Weak Data Part 3: Prepping the Model Dataset
December 12, 2024Kristin Scholten

Use cases
Streamlining Infrastructure Risk Analysis with Fused
December 11, 2024Jacob Prince-Bieker

Use cases
Map Overture Buildings and Foursquare Places with Leafmap
December 10, 2024Qiusheng Wu, Plinio Guzman

Use cases
From query to map: Exploring GeoParquet Overture Maps with Ibis, DuckDB, and Fused
December 6, 2024Naty Clementi

Use cases
Creating an app to model road mobility networks in Lima, Peru
December 5, 2024Claudio Ortega

Use cases
Beyond RGB: Interactive Exploration of NEON's Hyperspectral Data
December 3, 2024Guillermo Ponce

Use cases
How DigitalTwinSim Models Wireless Networks with DuckDB, Ibis, and Fused
November 26, 2024Sameer Lalwani
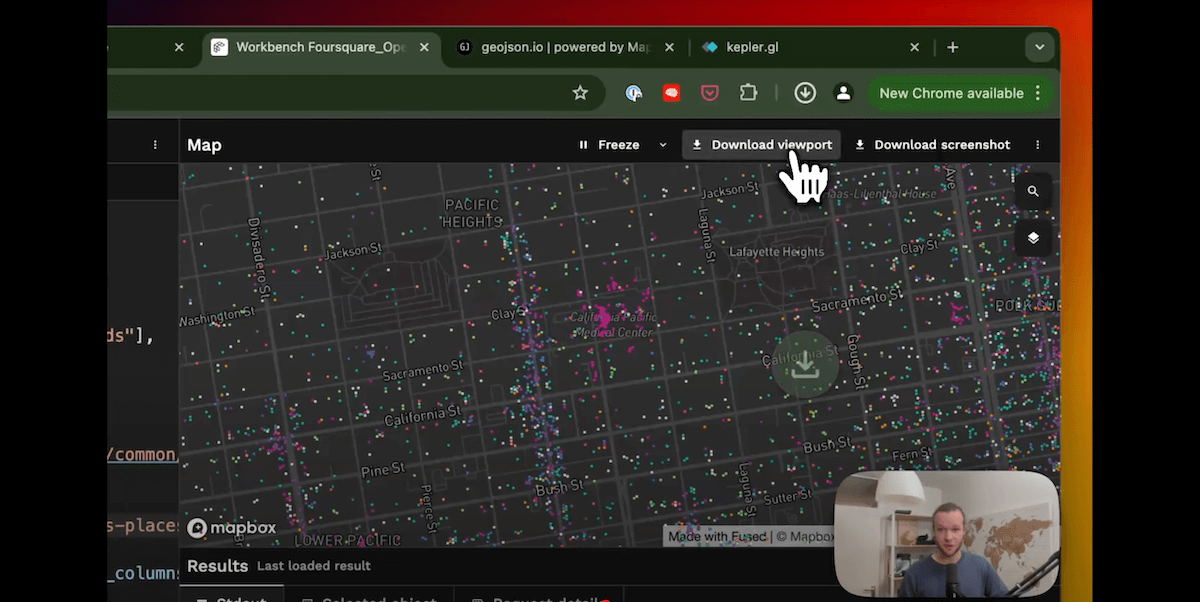
News
The Fastest Way to Download Foursquare's new POI Dataset
November 21, 2024Max Lenormand, Sina Kashuk

Use cases
How I Got Started Making Maps with Python and SQL
November 4, 2024Stephen Kent

Use cases
Discovering NYC Chronotypes with Fused
October 30, 2024Elizabeth Cutrone

Use cases
Earth-scale AI pipelines for Earth Observation (Part 1: Data Curation)
October 29, 2024Gabriel Durkin

Use cases
DuckDB, Fused, and your data warehouse
October 24, 2024Stefano Bourscheid

Use cases
The Strength in Weak Data Part 2: Zonal Statistics
October 22, 2024Kristin Scholten

News
Blazing Fast Geospatial SQL in DuckDB
October 17, 2024Isaac Brodsky

Use cases
Analyzing traffic speeds from 100 billion drive records
September 25, 2024Christopher Kyed

Use cases
Creating cloud-free composite HLS imagery with Fused
September 24, 2024Marie Hoeger, Plinio Guzman

Use cases
The Strength in Weak Data Part 1: Navigating the NetCDF
September 23, 2024Kristin Scholten

Use cases
Enrich your dataset with GERS and create a Tile server
September 19, 2024Jennings Anderson, Plinio Guzman

Use cases
The App That Finds Your City's Rainfall Twin Globally
September 17, 2024Milind Soni

Use cases
Six ways to use Fused
September 12, 2024Daniel Jahn

Use cases
AI for object detection on 50cm imagery
September 5, 2024Jeff Faudi

Use cases
Summarizing building energy ratings
September 3, 2024Isaac Brodsky

Use cases
ML-less global vegetation segmentation at scale
August 29, 2024Kevin Lacaille

Use cases
How Pachama creates maps on-the-fly with Fused
August 27, 2024Andrew Campbell, Plinio Guzman

News
Geospatial workflows of any size
April 22, 2024Isaac Brodsky, Matt Forrest
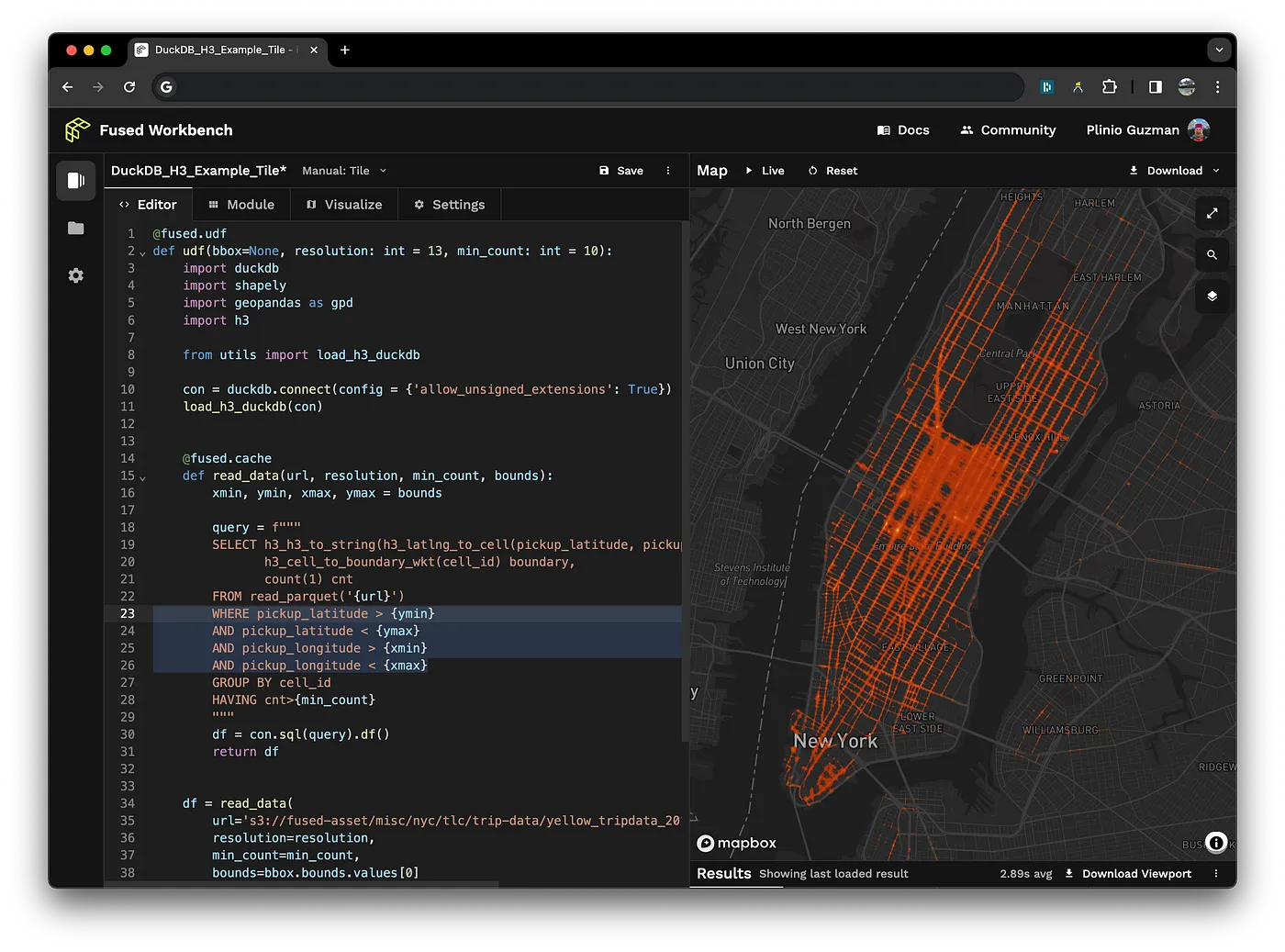
Technical blogs
DuckDB + Fused: Fly beyond the serverless horizon
April 9, 2024Sina Kashuk, Isaac Brodsky
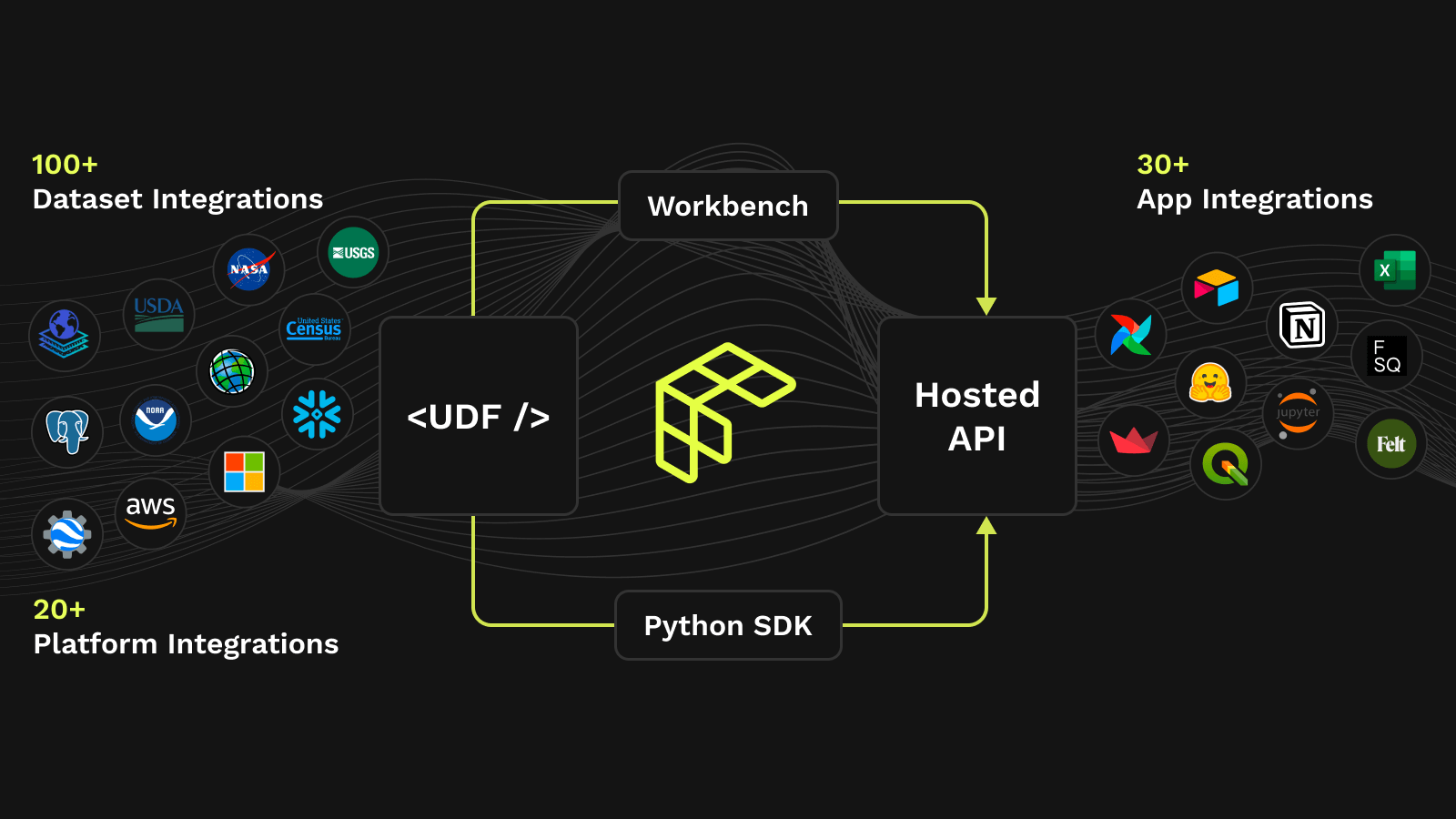
News
Fused redefines geospatial with instant maps
March 6, 2024Sina Kashuk, Isaac Brodsky

Technical blogs
Founder's blog post: why Fused?
March 1, 2024Sina Kashuk, Isaac Brodsky