Zonal stats with Fused: 10 minute guide
A step-by-step guide for data scientists.
Requirements
- access to Fused
- access to a Jupyter Notebook
- the following Python packages installed locally:
1. Using Fused for a Zonal Statistics Example
In this guide, we'll estimate how much alfalfa grows in zones defined by polygon geometries. This will show you how to:
- Bring in your data
- Write a UDF to process the data
- Run the UDF remotely & in parallel
- Create an app that shows your results and can be shared with anyone
2. Bring in your data
You'll first upload your own vector table with fused.ingest. This spatially partitions the table and writes it in your specified S3 bucket as a GeoParquet file. You'll then calculate zonal stats over a raster array of alfalfa crops in the USDA Cropland Data Layer (CDL) dataset.
This example shows how to geo partition polygons of Census Block Groups for Utah, which is a Parquet table with a geometry column. You can follow along with this file or any vector table you'd like. Read about other supported formats in Ingest your own data.
First, set up a local Python environment, install the latest Fused SDK with pip install fused, and authenticate.
Now, write the following script to geo partition your data. Pass the URL of the table to fused.ingest. When you kick off an ingest job with run_remote, Fused spins up a server to geo partition your table and writes the output to the path specified by the output parameter. In the codeblock below, fd://tl_2023_49_bg/ is the base path to your account's S3 bucket.
import fused
job = fused.ingest(
input="https://www2.census.gov/geo/tiger/TIGER2023/BG/tl_2023_49_bg.zip",
output="fd://tl_2023_49_bg/"
)
job_id = job.run_remote()
After running the preceeding code, open fused.io/jobs to view the job status and logs.
Once the job is complete, you can preview the output dataset in the File Explorer.
You can also ingest data without installing anything by using this Fused App.
For the next step you can use the path to the data you just ingested or, if you prefer, this public sample table: s3://fused-asset/data/tl_2023_49_bg/.

3. Write a UDF to process the data
To see the data as we process it, we will write a UDF in the Fused Workbench. As you write code in the UDF Builder you'll see how visualization results, logs, and errors show up immediately.
To write a UDF simply wrap a Python function with the decorator @fused.udf.
The first parameter of this UDF, bounds. It is reserved for Fused to pass a GeoDataFrame which the UDF may use to spatially filter datasets, and usually corresponds to a web map tile. This enables Fused to run the UDF for each tile in the viewport to distribute processing across multiple workers.
The year parameter is used to structure the S3 path of the CDL GeoTiff which the utility function read_tiff reads for the area defined by bounds. The crop_id parameter 36 corresponds to alfalfa the CDL colormap, which the UDF uses to mask the raster array.
Fused lets you import utility Modules from other UDFs with fused.load. Their code lives in the public UDFs repo.
read_tiffloads an array of the CDL dataset for the specifiedboundsextent andyeartable_to_tileloads the table you geo partitioned for the specifiedboundsextentgeom_statscalculates zonal statistics by aggregating thearrvariable over the geometries specified by thegdf
@fused.udf
def udf(
bounds: fused.types.Bounds = None,
year: int = 2020,
crop_id: int = 36
):
import numpy as np
# Convert bounds to tile
utils = fused.load("https://github.com/fusedio/udfs/tree/bb712a5/public/common/").utils
zoom = utils.estimate_zoom(bounds)
tile = utils.get_tiles(bounds, zoom=zoom)
# Load CDLS data
arr = utils.read_tiff(
tile,
input_tiff_path=f"s3://fused-asset/data/cdls/{year}_30m_cdls.tif"
)
# Mask for crop
arr = np.where(np.isin(arr, [crop_id]), 1, 0)
# Load polygons
gdf = utils.table_to_tile(
bounds,
table='s3://fused-asset/data/tl_2023_49_bg/',
min_zoom=5,
use_columns=['NAMELSAD', 'GEOID', 'MTFCC', 'FUNCSTAT', 'geometry']
)
gdf.crs = 4326
# Calculate zonal stats
return utils.geom_stats(gdf, arr)
Try running the UDF in the UDF Builder and visually inspect the output on the map. See what happens when you change year. Try introducing print statements such as print(arr) and print(gdf) to show logs in the console.
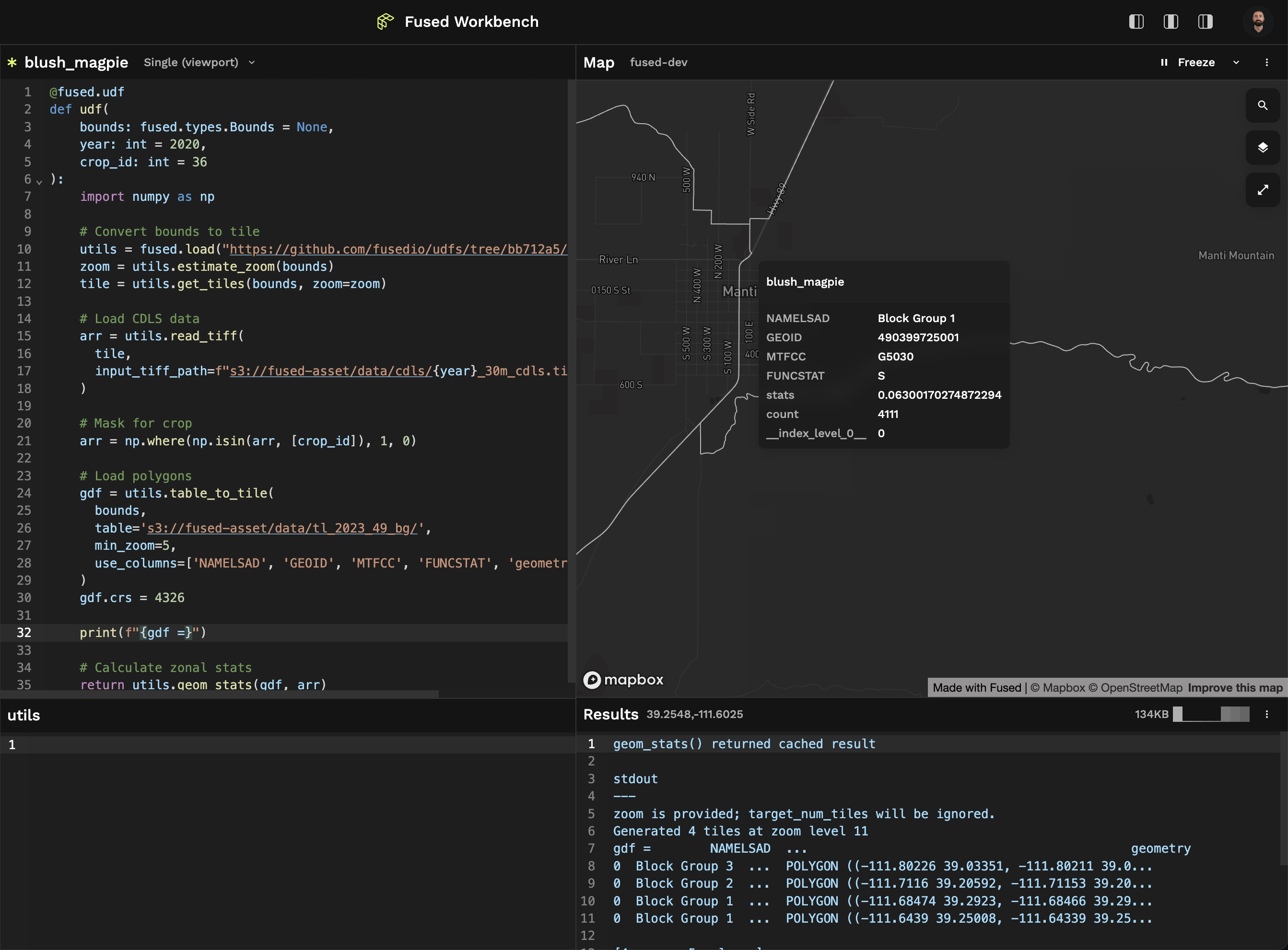
You might receive a timeout error in the Results tab. Try zooming into Utah on the map where the zonal areas are highlighted, to reduce the size of the tile being passed into the UDF from the map.
You can also style the map layer by setting this JSON in the Visualization tab
{
"tileLayer": {
"@@type": "TileLayer",
"minZoom": 0,
"maxZoom": 19,
"tileSize": 256,
"pickable": true
},
"rasterLayer": {
"@@type": "BitmapLayer",
"pickable": true
},
"vectorLayer": {
"@@type": "GeoJsonLayer",
"stroked": true,
"filled": true,
"pickable": true,
"lineWidthMinPixels": 1,
"pointRadiusMinPixels": 1,
"getFillColor": {
"@@function": "colorContinuous",
"attr": "count",
"domain": [
0,
100
],
"colors": "Tropic",
"nullColor": [
184,
14,
184
]
},
"getLineColor": [
208,
208,
208,
40
]
}
}
4. Run the UDF remotely and in parallel
Now that you have a UDF, let's see three ways you can Run UDFs remotely:
- via an HTTP endpoint,
- in a Python application,
- in parallel.
a. HTTP endpoint
Save the UDF, then click the 'Share' button located below the UDF name on the left side. In the dialog, click 'Share' again to generate a token. Once the token is created, you'll see an HTTP endpoint that you can use to call the UDF from anywhere. Try it out by changing the endpoint's query parameters — notice here ?dtype_out_vector=geojson, meaning the output will be a GeoJSON file.
https://www.fused.io/server/v1/realtime-shared/fsh_46eSFZaR3q3SnoVB28pN0g/run/tiles/12/778/1548?dtype_out_vector=geojson&crop_id=36&year=2020
What just happened?
When you called the HTTP endpoint, Fused ran the UDF then sent back the output table and debug logs. In the URL above, /12/778/1548 specifies the ZXY tile index to structure bounds and dtype_out_vector=geojson specifies the output format. Fused passes the year & crop_type parameters to the UDF as int based on their types in the function definition.
Why does this matter?
You called the HTTP endpoint with a shared token, which means any application may call the UDF and get data back without needing to configure credentials. You also passed parameters to the UDF, which enables you to dynamically generate data and define its output format.
To start seeing the full power of Fused, change the UDF code, save it, and call the endpoint again. You'll see the UDF automatically updates. When you call the UDF again it should run even faster.
b. Python SDK
The share token also enables you to run the UDF in a Python environment. You can specify bounds as the same map tile as above by passing x, y, and z parameters.
import fused
fused.run("fsh_46eSFZaR3q3SnoVB28pN0g", x=778, y=1548, z=12)
If you haven't installed GeoPandas at this point, the data in the geometries column may appear as unparsed binary values from the GeoParquet file.
You can also pass a GeoDataFrame to explicitly define a custom bounds and other parameters specific to the UDF.
import geopandas as gpd
# Square AOI near Utah Lake
bounds = gpd.GeoDataFrame.from_features({"type":"FeatureCollection","features":[{"type":"Feature","properties":{"shape":"Rectangle"},"geometry":{"type":"Polygon","coordinates":[[[-112.01315665811222,40.13628586159681],[-111.89330615564467,40.13628586159681],[-111.89330615564467,40.004073791892196],[-112.01315665811222,40.004073791892196],[-112.01315665811222,40.13628586159681]]]}}]})
fused.run("fsh_46eSFZaR3q3SnoVB28pN0g", bounds=bounds, year=2020, crop_id=36)
c. Parallelization
Invoke the UDF in parallel with run_pool to increase performance when you want to run it repeatedly with different input parameters. In this case, we'll use it to call the UDF across a set of years. For a deeper dive, read how to Call UDFs asynchronously.
import pandas as pd
def run_udf(year):
gdf = fused.run("fsh_46eSFZaR3q3SnoVB28pN0g", bounds=bounds, year=year, crop_id=36)
gdf['year'] = year
return gdf
utils = fused.load("https://github.com/fusedio/udfs/tree/e1fefb7/public/common/").utils
gdfs = utils.run_pool(run_udf, [2019, 2020, 2021])
gdf_final = pd.concat(gdfs)
gdf_final
These examples show how you can easily integrate Fused into your analytics workflows. For example, you can group gdf_final by GEOID and year and calculate aggregates of the count and stats columns.
gdfs.groupby(['GEOID', 'year']).agg({'count':'sum', 'stats': 'mean'}).reset_index()
5. Create an app
Now that you've created a UDF and explored different ways to invoke it, you can create a data app to share your results. We'll structure the HTTP endpoint you created above to act as a Tile server (with /run/tiles/{z}/{x}/{y}), allowing it to be called from a pydeck TileLayer within the Fused App Builder. We'll also create a Streamlit dropdown for users to set the year parameter.
Click "Copy shareable link" to share the app with others or embed it in Notion!
6. Conclusion and next steps
We've shown how you can use Fused to develop a distributed Python workflow to power an app. Through a simple sequence of steps we loaded data, wrote analytics code, and created an app to interact with the data. With a single click you went from experimental development code to a live application.
We hope this overview gives you a glimpse of what you can build with Fused. You can continue to learn how to get data in, transform data, and integrate with other applications.
Find inspiration for your next project, ask questions, or share your work with the Fused community.