Streamlining the design of parcel delivery routes with H3

TL;DR GLS uses Fused to create internal tooling to optimize routing for parcel delivery operations.
In the parcel delivery business, geospatial analyses are crucial to answer questions about daily operations. Do delivery drivers visit the same regions each day, letting them know their areas intimately? Or is there a high volatility of the regions? And of course, how do we optimize the routes of multiple drivers servicing the same region?
Those are the questions Antonius is working on at GLS Studio, an innovation lab by GLS (General Logistics Systems) which is an international parcel delivery service provider.
In this blog post, Antonius highlights how he uses Fused to create stable delivery areas for single-day and multi-day aggregates.
The Challenge Designing Delivery Areas
While the planned areas of driver tours to delivery packages can be rather well-defined, an evaluation of the areas actually served by drivers is equally important and might not be as easy. It can be used for guiding delivery drivers to become more efficient while also enabling managers to identify planned areas that are suboptimal due to built environment features like rivers or big highways.
Creating delivery areas out of single geospatial data points is challenging. A naïve approach would be to use convex polygons, but this causes multiple issues:
- A single data point can have a high influence on the shape and area of the polygon
- A tour consisting of multiple not connected sub-areas is hard to detect and correctly display
- This limits the area to what is covered by historic data which leaves a gap in new target regions
- Calculations using polygons are computationally expensive, hindering ad-hoc changes to the selected time span or the calculation parameters
Building new and sometimes experimental features means that the database is often not optimized for the use case. Data needs to be joined between multiple tables and even between multiple data sources. Therefore, fetching all data can be slow, highly limiting the usefulness of having an experimental feature to play around with.
Solving the Challenge with H3 and Fused UDFs
Dynamic Delivery Areas with H3
The solution to the first problem came by using H3 cells instead of polygons. By assigning cells to the drivers based on their historic deliveries to the cell, driver areas result automatically. Using H3 cells across different resolutions also allows us to represent the differences between urban and rural areas which see different parcel volumes. While there exists one "base resolution" to ensure non-overlapping and complete areas, the logical hierarchy among H3 cells can be used to calculate on lower resolutions for rural areas that see fewer deliveries, speeding up the computation and ensuring a broader coverage of those areas beyond the historical data points.
On the other hand, disputed H3 cells can be broken down to a higher resolution and assigned to different drivers or, when the "base resolution" has been reached, assigned to the driver delivering most parcels to the cell. As H3 cells have clearly defined neighborhoods, areas can easily be extended beyond their historical limits when desired, covering the empty space around to include a new parcel that falls outside of historically served area boundaries.
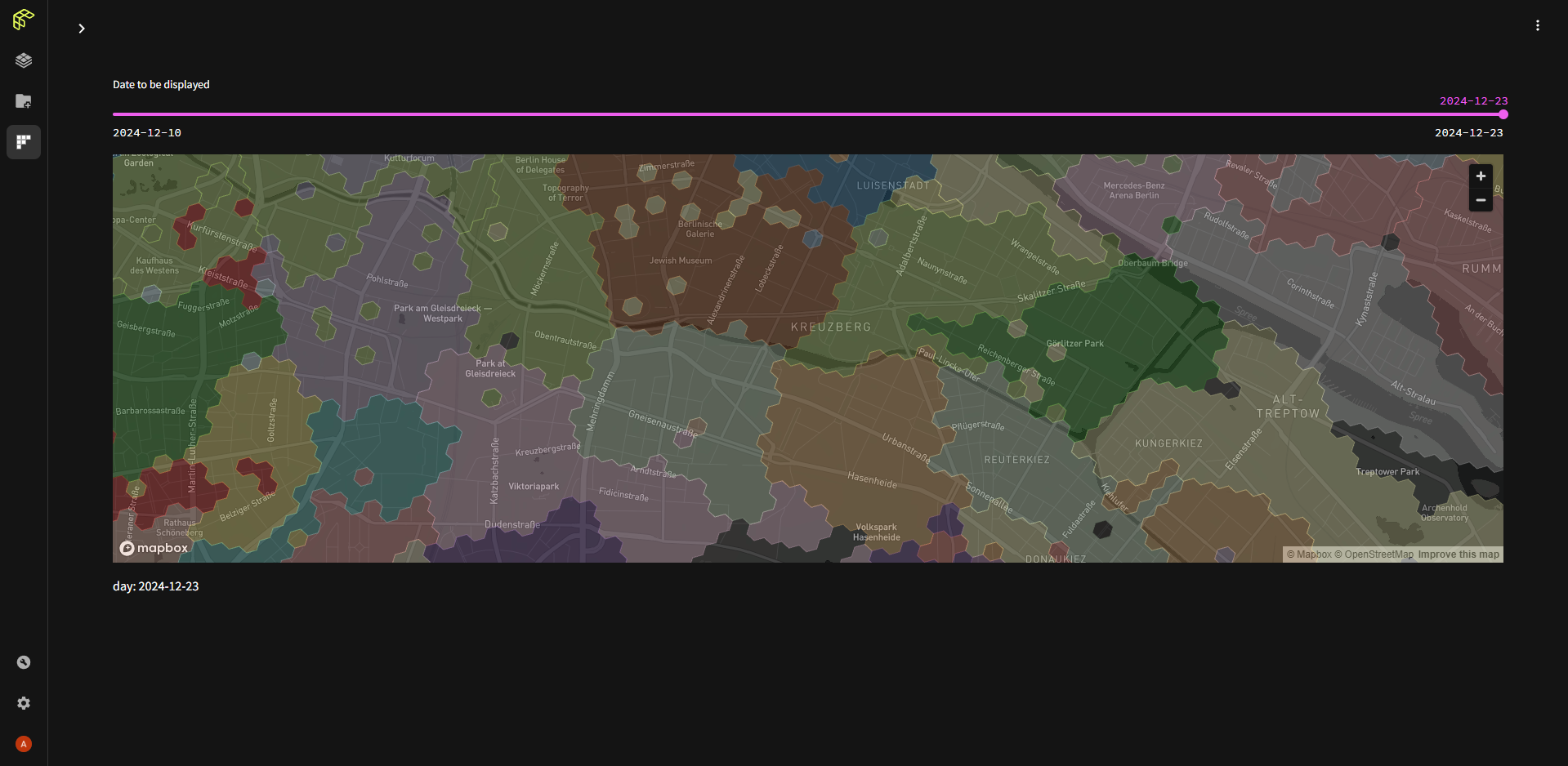
Fused app to show dynamic delivery areas at different H3 resolutions.
Streamlining workflows with Fused UDFs and Caching
Fused UDFs helped us solve problems around the latency of querying and calculations. When a user looks at an area for a day, they are probably interested in the same area on some of the previous and following days as well, right? So why not pre-calculate that already?
Using Fused, it is simply a matter of fire-and-forget to trigger the UDF with parameters for some previous and following days which are then already running to cache. So when the user views an adjacent day, the data will already be there. And more broadly, when it is possible to limit the number of parameter combinations in an experimental feature to a manageable amount, this fire-and-have-it-cached approach is not limited to caching data from previous and following days, but can also be used for a range of other cases.
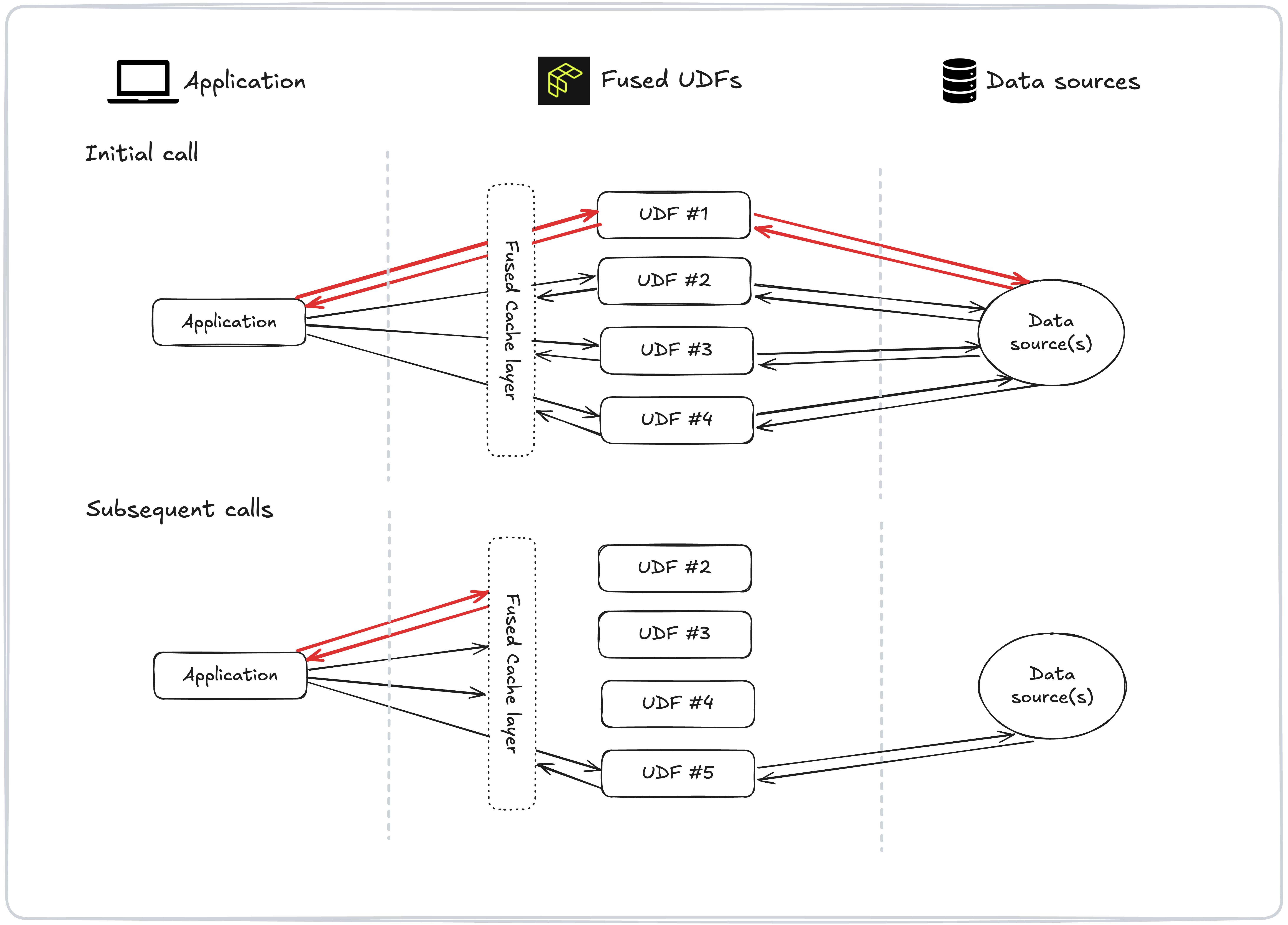
Sample workflow with Fused UDFs.
Conclusion
When developing new features that are not yet supported by the current data infrastructure, Fused UDFs enabled us to easily test things without having to change the underlying infrastructure in advance. The UDFs are easily shareable and adjustable, allowing testing by multiple people without having to run code locally while automatically making sure everyone is using the same code that is hosted in the UDF. And because we can easily call UDFs with HTTPS endpoints, when we have verified the feasibility of a feature, it's easy to integrate into our product.