The Modern Data Stack Is Dead. Who Killed It?



TL;DR The modern data stack (ETL + warehouses + orchestration tools) is breaking down. AI can now write transformations and queries. The new bottleneck is running that code safely, at scale. Fused is a serverless execution layer for data and AI workflows.
Fused is a serverless execution layer for data and AI workflows. With Fused, teams can write simple Python functions and run them at scale—directly on their data—without having to manage any infrastructure.
We have a murder on our hands.
The victim? The modern data stack. For years, data teams have relied on a patchwork of tools: ETL pipelines, warehouses, orchestration layers, and dashboards. Getting anything done often meant stitching together 5-6 different systems just to move and transform data. Something changed. The modern data stack wasn’t killed by one company or project. It was replaced by a shift across the entire ecosystem. We've rounded up the suspects as to who may have been at the scene of the crime, and we're going to round them up one after the other.

Suspect A: AI Code Editors
The most obvious suspect at this crime scene is AI.

Claude Code, OpenAI Codex, and Cursor are everywhere now and have radically transformed how data teams write and ship code. While AI hasn't fully replaced software engineers (yet), it has changed how we write code.
As an example, our Developer Advocate, Max, never took the time to learn SQL but has seen a huge unlock in using AI models to write more and more complex queries — without needing to memorize every piece of SQL syntax.
Our own Fused docs have shifted from being written purely for human developers to being written for human and AI developers, with things like simple llms.txt files that let AI models easily parse documentation and make sense of it.
It would however be all too simple to pin this crime on the AI scapegoat. The inspection is probably worth continuing a little further.
Suspect B: S3 + Parquet
Our next suspect is actually two working in tandem.
File formats like Parquet allow large, partitioned files that store massive amounts of data directly on cloud storage — no complex database systems required. Parquet files are fast to read and write, and they're portable: openable anywhere, downloadable to disk, and compatible with everything from pandas in Python to DuckDB natively. They really shine when paired with cloud storage, since most modern libraries can read and write to the cloud directly:
import pandas as pd
# Read from cloud
df = pd.read_parquet("s3://bucket/file.parquet")
# Transform
df = ...
# Save
df.to_parquet("s3://bucket/processed_file.parquet")
Data management doesn't simply go away — it still requires clever sorting and partitioning so files are efficient to find and read. But all of that is now possible directly in Parquet files stored on a cloud bucket.
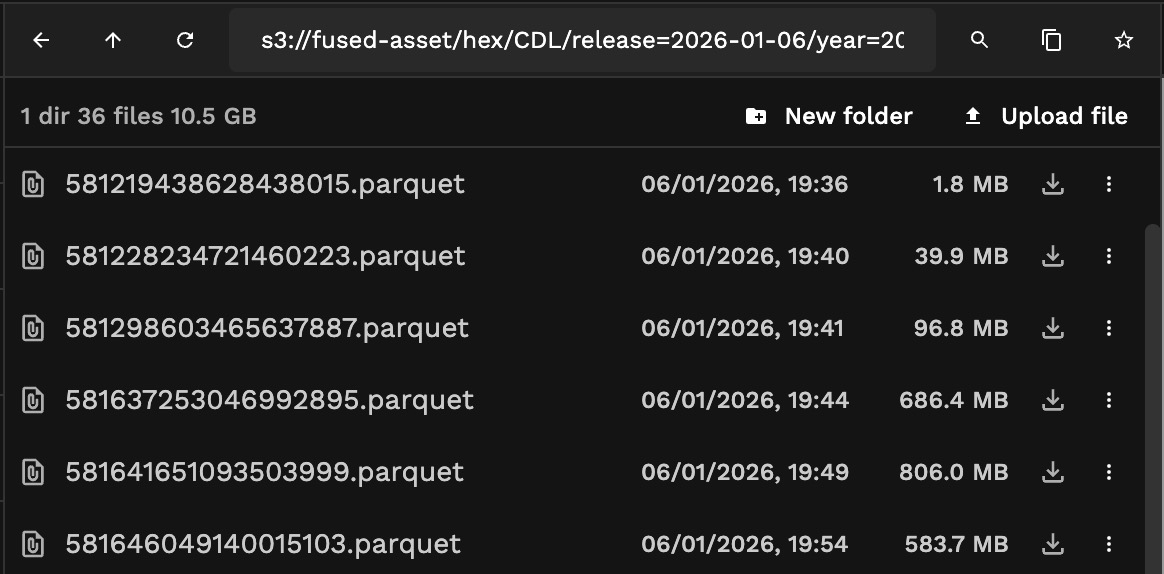
Example of the USDA's Crop Data Layer dataset converted to H3 hexagons for partitioning, stored in Parquet files directly on S3. Each file covers a specific area of interest and each Parquet file is partitioned to access only a specific row group of data.
This leads us naturally to the next suspect: query engines that make it trivially easy to read from a whole directory of Parquet files.
Suspect C: DuckDB
DuckDB is a top-tier suspect — close to the victim, practically family. A relative of the modern data stack that may have committed the crime on its own kin.
DuckDB is an open-source, in-process analytical database management system. Beyond the technical jargon: it lets you write SQL without needing a dedicated server to manage, and it runs incredibly fast on columnar data. It also queries a directory of Parquet files hosted on an S3 bucket directly, treating them like a database.
-- Searching for a specific ID across 50GB of parquet files on S3 is a single query now
SELECT *
FROM read_parquet('s3://overturemaps-us-west-2/registry/*.parquet')
WHERE id = 'fea28f69-7afa-460c-b270-61ef74cd340c';
This lets you take a simple query, run it from a laptop, and scale it to huge amounts of data on S3. Engines like DuckDB are optimized for analytics and benefit from Parquet's partitioning, which can skip entire files and row groups.
Large queries that would blow up in a regular pandas run are now possible in-memory with minimal setup:
SELECT
user_id,
count(*) AS event_count,
approx_quantile(duration_ms, 0.95) AS p95
FROM read_parquet('s3://bucket/events/*.parquet')
GROUP BY user_id;
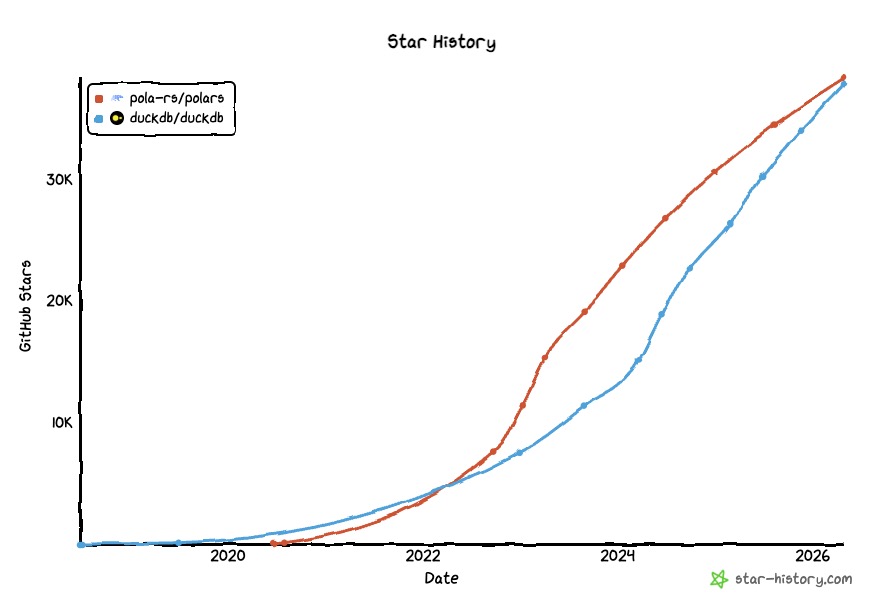
DuckDB is our main example here, but the pattern is bigger. Other engines like Polars reflect the same shift: open formats on object storage plus a query runtime that can move to the data. At the time of writing, the two libraries are neck and neck and DuckDB is gaining steam over Polars.
DuckDB makes even more sense in a world where LLMs have gotten incredible at writing even complex SQL queries, lowering the bar to entry dramatically. That makes DuckDB a prime suspect in our case.
Suspect D: Serverless
Doing anything with data used to require a fleet of big servers. Code couldn't run without access to data, and that access lived on the servers. The servers had to be big because Spark jobs run out of memory and crash. Anyone who's tried to debug a crashing data processing job knows the feeling of hunting through logs looking for suspects and clues.
That brings us to our fourth suspect: serverless, elastic compute. Serverless removes layers of orchestration from the user's way, making it easier to scale processing on demand, simplifying and speeding up iteration cycles.
Serverless also plays well with all the other suspects: access to cloud storage is native and natural; DuckDB starts quickly, avoiding the cold-start tradeoff.
The Verdict
The modern data stack wasn't killed by one thing. It was killed by a shift across the whole stack:
- Large datasets can now be managed directly in the cloud, no additional management systems required.
- Analytical engines like DuckDB can query all of this data directly.
- AI makes it cheap to write the glue code.
The bottleneck moved from "writing transformations" to "running code safely, at scale, with credentials, reproducibility, and a stable interface."
So What Should It Look Like Instead?
Claude Code lets you build at the speed of your ideas. Teams can ship faster (we're seeing this at Fused), people who didn't have time to code anymore can now code again, and project backlogs are being filled.
But Claude can't directly ship. It can help you write the code, but that's not enough. We see two paths forward:
Approach 1: Give Claude Code More and More Access
Give it a credit card, a dedicated EC2, your database credentials. This is what we're seeing with fully autonomous AI models.
While this works nicely for a local solo project, it doesn't scale to enterprise customers that need tight security and proper scope. You can't manage access across a whole team with proper permissions this way.
Approach 2: Give Claude Code Easy Access to Scoped Processing
Ideally this means giving your AI agent:
- Serverless compute: Spin up a node when you need it, scale on demand. The simpler to call, the better Claude can use it.
- Sandboxed, secure access: Claude shouldn't be able to wreak havoc in your codebase or data. Projects should have clear permissions, and data access should be controlled (don't let data from customer A be exposed to customer B).
The catch: now you need to manage an infra layer that scales up and down, handles auth, and manages permissions across teams. These are all things you want your AI agents to have access to — but probably not something you want to maintain yourself.
Our Answer: Why We're Building Fused
We've been building Fused for data teams that need to get work done and have customers who need answers no matter where their data comes from.
Built on Python
Python is the language of data. Whether you're loading from S3, Snowflake, or Google Drive — or extracting from a PDF, scraping a website, or processing a one-time download — there's a way to do it in Python. It's the most versatile tool for working with any data, regardless of type, origin, or size.
We ship an opinionated and tested set of dependencies that covers most modern data use cases, so data scientists and engineers can start building in seconds, not hours.
Scalable Serverless Engine
Python alone isn't enough. Scaling up compute on demand normally means building and deploying Docker containers. Fused lets you create User Defined Functions — simple, self-contained Python functions that run on our serverless compute infrastructure. All you need is a @fused.udf decorator:
@fused.udf
def udf():
import pandas as pd
return pd.read_parquet("s3://fused-sample/demo_data/airbnb_listings_sf.parquet")
You can call thousands of jobs at the same time:
@fused.udf
def udf():
basic_example = fused.load('process_data') # Load existing UDF
results = basic_example.map(range(100_000), max_workers=500) # Run in parallel
return results.df()
This spins up as many nodes as needed under the hood.
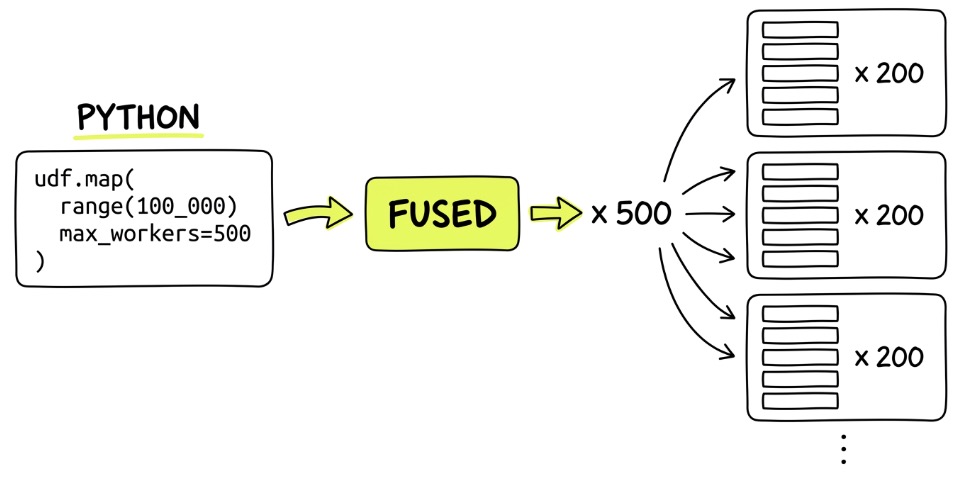
To put the performance in perspective: two thousand 90-second jobs can be done in 120 wall-clock seconds with Fused. That's only 30 seconds of total orchestration overhead across 2,000 concurrent, completely independent jobs — each on a dedicated 4-core machine with 10 GB of RAM. That's 0.015 seconds of overhead per job.
For context: a regular EC2 instance of 128 cores takes ~2 minutes just to turn on.
Fused turns on the machine, installs dependencies, authenticates credentials, and completes a 90-second job in the same time it takes that EC2 instance to boot.
The takeaway
AI is writing the code. Open formats are simplifying data. Serverless is removing infrastructure. What’s missing is a way to run all of this reliably.
That’s what we’re building with Fused.
Try Fused
You can try it out yourself at fused.io/workbench or read the docs to learn more.